
Help! The crustaceans have taken over my Homelab!
OpenClaw with Ollama serving gpt-oss-120b.

Anyone exposed to the current trends couldn’t have missed the whole hype around Clawdbot/Moltbot/OpenClaw last week. Needless to say I got pulled into this right at the moment I was also setting up my local LLM.

I was setting up a local LLM via Ollama to serve a couple of models, the main being gpt-oss-120b. I am also installing ComfyUI for some basic image generation.
While its true that gpt-oss-120b is not the latest one, my experience and general opinion has been this is the best model to run locally if your system allows. My Strix Halo machine has been setup with Ubuntu and 96GB of RAM dedicated for the inference.
There were a few hiccups, mainly because I was installing it when the team was switching between Moltbot and Openclaw and some documentations were also changing fluidly.
Here are few pointers if you are trying the same.
If you remember my previous post, I had a Ubuntu Dell Laptop lying around without much responsibility. I did consider spinning up a VM in my (other) Proxmox machine, but then decided to use this laptop for it. The first thing I did was create a dedicated user in the system and install Openclaw under this user. This provides a sort of isolation from Openclaw bricking the laptop by mistake.
My Strix Halo machine is running the Ollama and opening up only the port to Ollama and that too from known IP address (of my Openclaw machine). This might cause some delay if you follow this approach.
You need to make sure that Ollama has sufficient Context Reset interval. When I tried with the defaults (keep-alive : 5 minutes) and the API was not sending this, it kind of went into a short-term memory loss situation.
You might already be doing this, but the Ollama context size should also be sufficiently higher (as much as your local rig allows). I kept it at 8192.

I also found that linking with Whatsapp was, although simple, weird. Because you are left with talking to yourself unless you get a dedicated e-sim for Openclaw. I might do that later, but for now, I moved to setup a bot in Telegram and this has been pretty smooth.
Finally, I was doing everything at once. Installing Ollama, gpt-oss, openclaw and routing between two local machines etc. Looking back, I would have taken a simpler approach. Maybe start with your claude as your model provider and then switch to local LLM once you have ironed out the issues with OpenClaw.
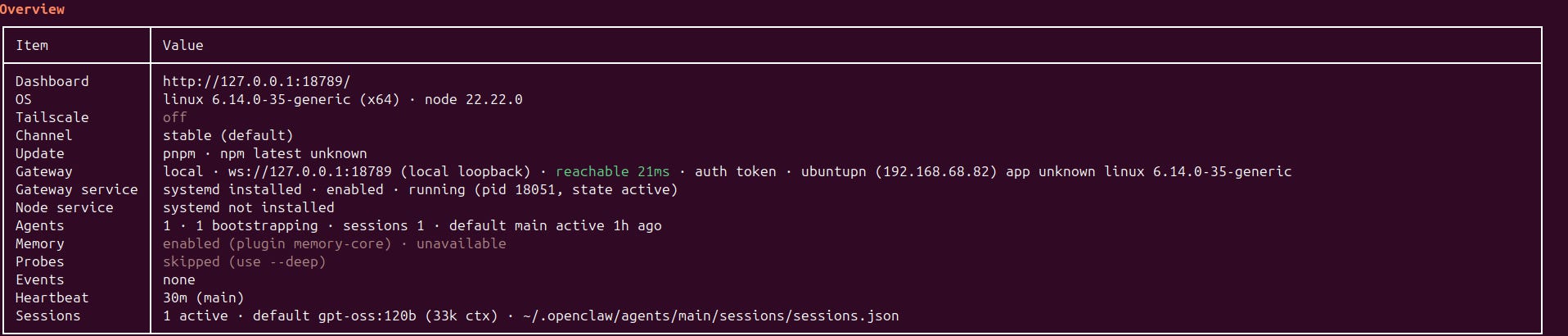
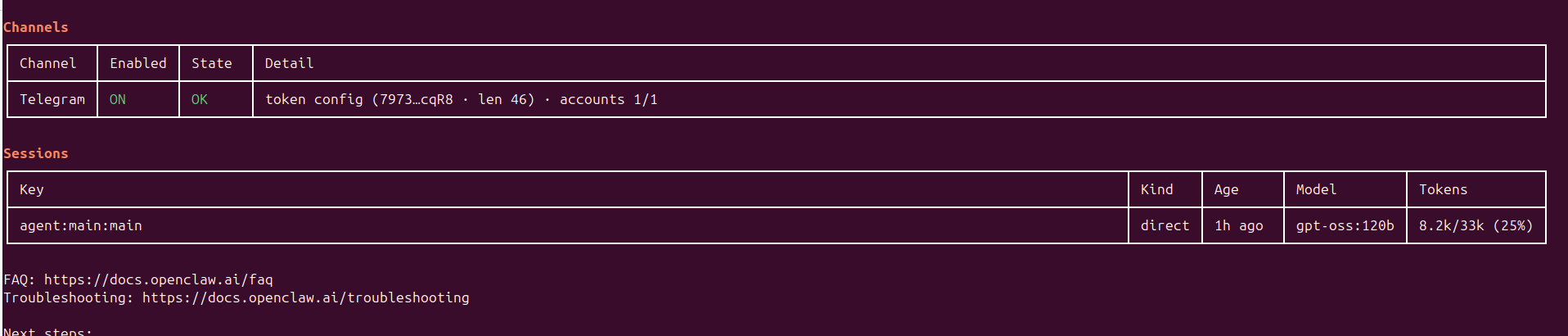
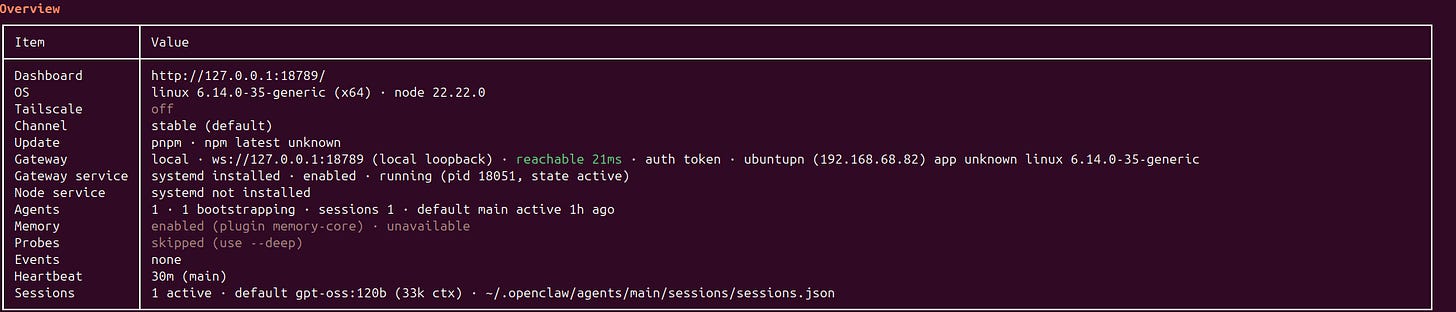
While it was definitely fun, I don’t think its sustainable to keep this approach if I want to make sure that the Openclaw is somewhat useful while I could reliably use my local rig for other AI experiments. So, sadly while this was a proof of concept that you could run Openclaw locally, I will be moving back to Claude. I can’t imagine anyone doing this, in their local laptop unless they dedicate it for this purpose. Maybe one day. Not now.
Let me know if you have tried something with Openclaw. I am curious to learn what use cases are going to surface up with this new tool.
Didn't expect that Dell laptop from your previous post to power an LLM! So smart.